如果有索引就好了
Background
最近的工作已经到达验收的里程碑.遇到一个功能的优化问题:导入数据, 将原始数据写入的同时按条件归并更新或新建统计信息. 导入几千条数据的时候发现导入时间特别长.由于近期看了 index 的原理, 希望能够从数据库层上解决性能问题, 尽可能地不动或者少动业务的写法.
以下是表的说明以及 sql 的说明, 使用的是 PostgreSQL.
SELECT
array_agg(raw_data.id) AS ids,
FROM raw_data
WHERE raw_data.field1 = '' AND raw_data.field2 = '启用Windows终端服务' AND raw_data.field3 = '172.24.84.108'
GROUP BY raw_data.field1, raw_data.field2, raw_data.field3
LIMIT 1;
SELECT *
FROM result
WHERE result.field1 = '' AND result.field3 = '172.24.84.108' AND
result.field2 = '启用Windows终端服务'
LIMIT 1;
提高归并和搜索的效率是需要解决的主要问题
Index
上面所提到搜索的问题很容易想到使用索引, 也确实是这样做的. 这里记录一些关于索引的知识.
提高搜索的效率,最直观的想法是: 数据按搜索关键字 K 有序排列,
这样我们就可以通过一些有效的算法减少搜索的时间复杂度.如图:
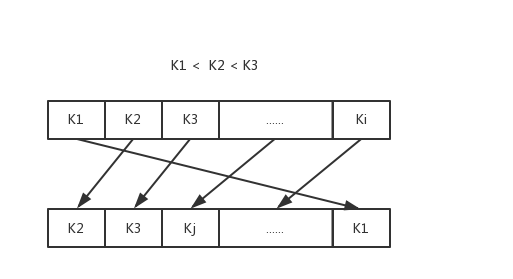
通过按K排序的结构我们可以通过简单的二分法可以找到符合条件的结果. 由于我们有了按K排序的结构, 我们就可以用更有效的数据结构组织这些已经记录使搜索更有效率. 如了解的 B+树结构或者 hash 结构. 由此又形成了以下的数据结构图:
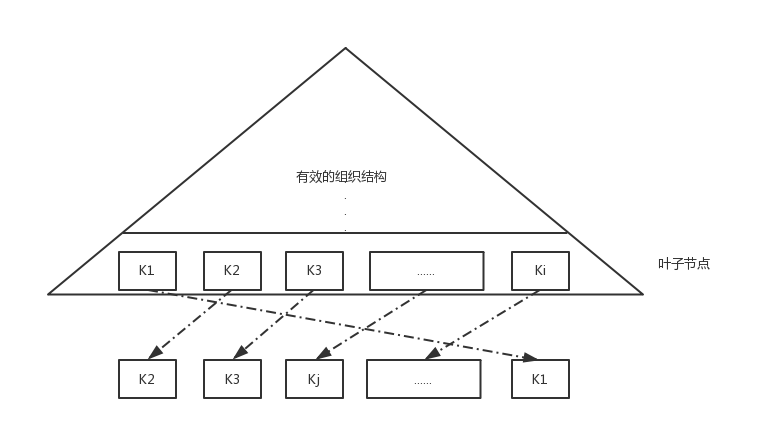
Clustered Index or unclustered Index
暂不考虑上图我们是如何组织有序结构. 先看叶子节点, 也就是index的最底层的节点.
在叶子节点中,最直观的就是存原始记录的存放地址,这样我们在搜索到 K 时,可以通过先拿到地址然后去找原始记录.
这样的索引我们称之为 unclusterd index, 简单的就是 index 数据结构中叶节点指向原始记录.
此索引结构有以下两点优势:
- 可以不要求原始记录的存储顺序;
- index 文件可以很小,因为只需要存地址即可;
看起来似乎并没有劣势的地方. 考虑操作系统的因素, 数据库的记录是存在磁盘等低速介质上的,如果记录随意存放将会造成缺页中断,
则需要更多的 IO 次数才能读取数据. 这里有一个经验数字,如果搜索匹配的记录占总数的 10% 时, 这种结构需要的页与紧凑排序的页相当.
也就是说如果我们可以预估搜索的记录占总记录的 10% 以下时, 使用 Unclustered Index 是比较合理的.
除了这种方法之外,还有另外一种index 类型: Clustered Index.
如果我们的叶子节点指向的data是相对紧凑的,就可以解决 Unclustered Index问题.
保持 data 的紧凑, 则要保持 data 相对有序, 这样虽然会带来搜索的效率但是插入和删除的开销将会非常大,不是很合适.
但是如果我们叶子节点存放的不是原始记录的地址而就是记录本身,这样就可以避免 Unclustered Index 存在的问题.
因此 Clustered Index 需要更大的空间.
数据库的记录需要有主键, 在主键上建立的索引称为 primary index, 一般来说, primary index 用的结构就是 Clustered Index.
另外我们可以添加多个索引, 在主键之外字段上建立的索引称为 secondary index, secondary index 可以使用 Unclustered Index.
PostgreSQL 中支持这两种结构, 但是在 MySQL 的 innodb 中使用的是特殊形式的 Cluster Index.
Dynamic B+ tree and static ISAM
我们再考虑 index file 中上层组织结构. 上层的组织结构有 dynaminc 和 static 两种组织方式.
static 的方式保持上层结构保持不变,则数据结构是固定的,可以利用满二叉树的存储方式可以顺序存储的原理,提高获取效率.
ISAM (Indexed Sequential Access Method) 就是这种静态的数据结构. 以下是数据结构图:
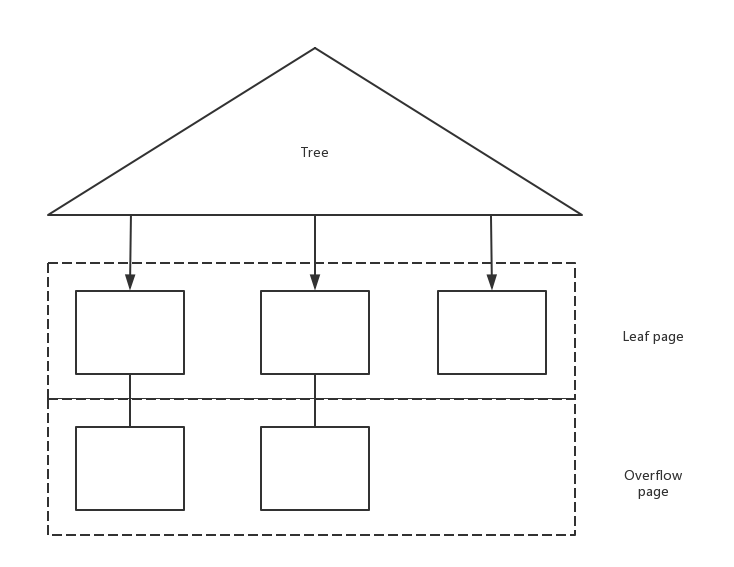
通过 overflow page 解决了数据的添加和删除, 对于 overflow page 中我们可以有序存放数据, 使用二分搜索查找,提高效率. 这样的结构存在问题, 如果 overflow page 挂的数据特别多,将会影响搜索效率.
动态的 index 结构如 B+ 树.
(略)
index 的作用
正如介绍中 SQL 语句一样, 如果我们的搜索 K 是组合键(K1, K2, K3),如何建立索引. 最直观的是想法是如果 (K1, K2, K3) 这个元组
可以排序即可. 那么这样的元祖是如何排序的? 这也是 Index 最左前缀匹配的原理, 首先按 K1 比较, 然后比较K2, 以此类推.
所以如果我们能够利用到索引,则搜索的条件应该按组合索引的顺序匹配.
index 的基本概念如上,另外如 hash 索引的动态或静态结构, 不同索引的搜索方式, 以及不同方式搜索的时间复杂度计算 由索引的数据结构决定,此处按下不表, 简单的讲 hash 索引用于等值搜索,不利于条件搜索, 用于等值搜索时使用的复杂度低, Tree 索引的在等值搜索和范围搜索中有优势. 如下简单记录一些 index 的作用.
- index 最重要的作用还是提高搜索效率, 提高搜索的效率还体现在 join 操作使用 index;
- 获取数据是由 index 做搜索获取的, 当考虑并发控制时 index 的结构会影响锁的粒度;
- 由于 index 可以是组合索引, 如果组合键能够满足搜索要求就可以采用 index-only 策略, 是搜索时可以不用取出原始的完整记录;
优化性能
根据上述的原理说明,我们可以确定使用组合索引, 可选采用 unclustered or clusted index, 数据结构可以选用 Tree or Hash index. 我采用的是 unclusetered and Tree index.
主要原因是采用了 SQLAlchemy 的 ORM 方式.
SQLAlchemy index 声明方式如下:
class Model(Base):
__tabel_args__ = (
Index('group_by', "field1", "field2", "field3"),
)
另外查询条件的顺序需要注意, 确保能够使用组合索引, SQLAlchemy 中的应该使用 filter 而不是 filter_by, 因为实际观察中filter_by
生成的 SQL 并非按传递的顺序.
优化的结果:数据不可见
总结: 单条数据,耗费时间能减少2-3倍左右